

データ分析ガチ勉強アドベントカレンダー 14日目。
時系列データでまず思いつくのは、株価のチャートですよね。 また、最近はやっている仮想通貨。私も最近coincheckに入金しました。
やっぱ、実際にお金が絡むとちゃんと勉強しようって言う気になる!笑
せっかくチャートを見るわけだし、その見方について勉強しておこうと思いました。 そしてせっかくなので、自分で実装してどういう仕組みなのかまで知っておこうと思いました。 理系だからね、分からないものを使うのは嫌だからね。
というわけで、Python(主にPandasとMatplotlibを用いながら)でテクニカル指標についてやっていきます。扱うデータは三年分の日経平均株価。
指標について知りたい人も、自分で実装してみたいという人もどうぞ。
- テクニカル分析とファンダメンタル分析
- 実装において
- ローソク足
- 1位 : 移動平均線
- 2位 : ボリンジャーバンド
- 3位 : MACD(Moving Average Convergence/Divergence)
- 4位 : RSI (Relative Strength Index)
- 5位 : 一目均衡表
- まとめ
テクニカル分析とファンダメンタル分析
大きく相場にはテクニカル分析とファンダメンタル分析の2つの分析手段がある。
- ファンダメンタル分析 : 情報を集め、価格がどうなるかを判断する。株で言えば会社の情報とか、仮想通貨で言えば技術的な要素とか方針とかそういうのかな?
- テクニカル分析 : チャート情報から、価格がどうなるかを判断する。チャートだけ見れば良いが、大変動などの予測は難しい。
一般的に、テクニカルのほうがとっつきやすいけど、判断を誤ることも多いと言われている。
トレーダーが良く使うテクニカル指標より、主要なテクニカル分析の指標を並べてみた。
| 順位 | テクニカル指標 | 割合 |
|---|---|---|
| 1位 | 移動平均線 | 36.6% |
| 2位 | ボリンジャーバンド | 17.1% |
| 3位 | MACD | 13.2% |
| 4位 | RSI | 8.4% |
| 5位 | 一目均衡表 | 8.4% |
| 6位 | ストキャスティクス | 7.1% |
| 7位 | フィボナッチ | 2.9% |
| 8位 | その他 | 6.3% |
これの、1位から5位までの指標について簡単に説明&Python実装する。
実装において
実装を見る方は、まず下記でデータを読み込んで置いてください。また、自分の好きなデータでもOKです。
いつものごとく、githubのノートブックに上げています。(day14)
# データの読み込み %matplotlib inline import pandas as pd import numpy as np import matplotlib.pyplot as plt from datetime import datetime def str2time(string): return datetime.strptime(string, '%Y/%m/%d') df_orig = pd.read_csv("stock_nikkei_3yrs.csv") df_orig.index = df_orig.date.apply(str2time) df_orig = df_orig.sort_index(ascending=True)
ローソク足
説明
チャートの代表。一つ一つのローソクを見ると、ひと目でその期間の動きが分かるようになっている。
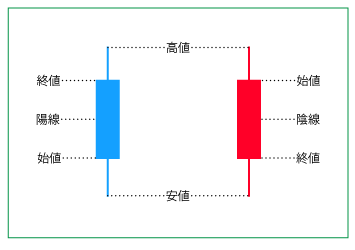
テクニカルチャート講座:ローソク足より引用

実装
import matplotlib.finance as mpf from matplotlib.dates import date2num df = df_orig[df_orig.index >= datetime(2017,7,1)] df_ohlc = pd.DataFrame(df[["open","high","low","close"]]) xdate = [x.date() for x in df_ohlc.index] #Timestamp -> datetime ohlc = np.vstack((date2num(xdate), df_ohlc.values.T)).T #datetime -> float fig = plt.figure(figsize=(15,5)) ax = plt.subplot() mpf.candlestick_ohlc(ax, ohlc, width=0.7, colorup='b', colordown='r') ax.grid() #グリッド表示 ax.set_xlim(xdate[-60], xdate[-1]) #x軸の範囲 fig.autofmt_xdate() #x軸のオートフォーマット
1位 : 移動平均線
説明

そのままのチャートはノイズ等も多く、価格が乱高下するので、その日からある期間分の平均を取るという操作を良くする。英語で言うとMoving Averageで、25MAだと25日分の移動平均線ということになる。平均を取ると、ノイズが無くなり、そのチャートのトレンドが明確に現れる。
また、2つの移動平均線を組み合わせることも多く、各線の交差するところをゴールデンクロス/デッドクロスと呼ぶ。
- 日足の場合、短期が25日、長期が75日
- 週足の場合、短期が13週、長期が26週
が基本らしい。
実装
df1 = df_orig.sort_index() df1["ma25"] = df1.close.rolling(window=25).mean() df1["ma75"] = df1.close.rolling(window=75).mean() df1["diff"] = df1.ma25-df1.ma75 # df1 = df.date.apply(datetime.timestamp()) df1["unixtime"] = [datetime.timestamp(t) for t in df_orig.index] plt.figure(figsize=(15,5)) xdate = [x.date() for x in df1.index] # line and Moving Average plt.plot(xdate, df1.close,label="original") plt.plot(xdate, df1.ma75,label="75days") plt.plot(xdate, df1.ma25,label="25days") plt.xlim(xdate[0],xdate[-1]) plt.grid() #Cross for i in range(1, len(df1)): if df1.iloc[i-1]["diff"] < 0 and df1.iloc[i]["diff"] > 0: print("{}:GOLDEN CROSS".format(df1.iloc[i]["date"])) plt.scatter(df1.iloc[i]["date"],df1.iloc[i]["ma25"],marker="o",s=100,color="b") plt.scatter(df1.iloc[i]["date"],df1.iloc[i]["close"],marker="o",s=50,color="b",alpha=0.5) if df1.iloc[i-1]["diff"] > 0 and df1.iloc[i]["diff"] < 0: print("{}:DEAD CROSS".format(df1.iloc[i]["date"])) plt.scatter(df1.iloc[i]["date"],df1.iloc[i]["ma25"],marker="o",s=100,color="r") plt.scatter(df1.iloc[i]["date"],df1.iloc[i]["close"],marker="o",s=50,color="r",alpha=0.5) plt.legend()
2位 : ボリンジャーバンド
説明

線を移動平均に引く
: 68%の確率で株価がそこに収まる
: 95%の確率で株価がそこに収まる
: 99%の確率で株価がそこに収まる
均衡状態の相場での正規分布を仮定しているので、 ここから外れた = 釣り合いが破れているということ。
不安定だが、売買のチャンスともいえる。
株の売買サインを簡単に見極めるボリンジャーバンドの使い方によると
実装
def Bollinger(df,window=25): df1 = df.copy() df1["ma"] = df1.close.rolling(window=window).mean() df1["sigma"] = df1.close.rolling(window=window).std() df1["ma+2sigma"] = df1.ma + 2*df1.sigma df1["ma-2sigma"] = df1.ma - 2*df1.sigma df1["diffplus"] = df1.close - df1["ma+2sigma"] df1["diffminus"] = df1["ma-2sigma"] - df1.close s_up = df1[df1["diffplus"]>0]["close"] s_down = df1[df1["diffminus"]>0]["close"] plt.figure(figsize=(15,5)) plt.grid() plt.scatter(s_up.index, s_up.values,marker="x",s=100,color="blue") plt.scatter(s_down.index, s_down.values,marker="x",s=100,color="red") xdate = [x.date() for x in df1.index] plt.plot(xdate, df1.close.values,label="close",color="b",alpha=0.8) plt.plot(xdate,df1.ma.values,label="{}ma".format(window)) plt.fill_between(xdate, df1.ma-df1.sigma,df1.ma+df1.sigma,color="red", alpha=0.7, label="$1\sigma$") plt.fill_between(xdate, df1.ma-2*df1.sigma,df1.ma+2*df1.sigma,color="red", alpha=0.3, label="$2\sigma$") # plt.fill_between(xdate, df1.ma-3*df1.sigma,df1.ma+3*df1.sigma,color="red", alpha=0.3, label="$3\sigma$") plt.legend() plt.xlim(xdate[0],xdate[-1]) Bollinger(df_orig,window=25)
3位 : MACD(Moving Average Convergence/Divergence)
説明
移動平均線を少し改良している。時系列は直近のデータのほうが昔のデータよりも価値が高い傾向にあるので、そういう平均のとり方をして、移動平均線を引いている(指数平滑移動平均線(EMA)という)。下記の2本の移動平均線を見ることで、そのトレンドを把握する。

実装
df_orig.head() df_orig["MACD"] = df_orig.close.ewm(span=12, min_periods=1).mean() - df_orig.close.ewm(span=26, min_periods=1).mean() df_orig["signal"] = df_orig.MACD.ewm(span=9, min_periods=1).mean() df_orig["macd_diff"] = df_orig["MACD"]-df_orig["signal"] xdate = [x.date() for x in df_orig.index] plt.figure(figsize=(15,10)) plt.subplot(211) plt.plot(xdate, df_orig.close,label="original") plt.xlim(xdate[0],xdate[-1]) plt.legend() plt.grid() plt.subplot(212) plt.title("MACD") plt.plot(xdate, df_orig.MACD,label="MACD") plt.plot(xdate, df_orig.signal,label="signal") plt.xlim(xdate[0],xdate[-1]) plt.legend() plt.grid(True) #Cross for i in range(1, len(df_orig)): if df_orig.iloc[i-1]["macd_diff"] < 0 and df_orig.iloc[i]["macd_diff"] > 0: print("{}:GOLDEN CROSS".format(df_orig.iloc[i]["date"])) plt.scatter(xdate[i],df_orig.iloc[i]["MACD"],marker="o",s=100,color="b") if df_orig.iloc[i-1]["macd_diff"] > 0 and df_orig.iloc[i]["macd_diff"] < 0: print("{}:DEAD CROSS".format(df_orig.iloc[i]["date"])) plt.scatter(xdate[i],df_orig.iloc[i]["MACD"],marker="o",s=100,color="r")
4位 : RSI (Relative Strength Index)
買われすぎ、売られすぎな相場では、投資家が不安になってくる。その心理状況を定量化しようとした指標。 値上がりと値下がりのバランスを見ている。

実装
def plot_RSI(df,window): diff = df_orig.close.diff(periods=1).values xdate = [x.date() for x in df_orig.index] RSI = [] for i in range(window+1,len(xdate)): neg = 0 pos = 0 for value in diff[i-window:i+1]: if value > 0: pos += value if value < 0: neg += value pos_ave = pos/window neg_ave = np.abs(neg/window) rsi = pos_ave/(pos_ave+neg_ave)*100 RSI.append(rsi) #RSIのグラフ描画 plt.plot(xdate[window+1:], RSI,label="RSI {}".format(window),lw=2.5,alpha=0.6) plt.xlim(xdate[window+1],xdate[-1]) plt.ylim(0,100) plt.legend() xdate = [x.date() for x in df_orig.index] plt.figure(figsize=(15,10)) plt.subplot(211) plt.plot(xdate, df_orig.close,label="original") plt.xlim(xdate[0],xdate[-1]) plt.legend() plt.grid() plt.subplot(212) plt.grid() plt.title("RSI") plot_RSI(df_orig,window=14) plot_RSI(df_orig,window=28) plot_RSI(df_orig,window=105) plt.fill_between(xdate,np.ones(len(xdate))*30,color="blue",alpha=0.2) plt.fill_between(xdate,np.ones(len(xdate))*70,np.ones(len(xdate))*100,color="red",alpha=0.2) plt.plot(xdate,np.ones(len(xdate))*30,color="blue",linestyle="dotted") plt.plot(xdate,np.ones(len(xdate))*70,color="red",linestyle="dotted") plt.show()
5位 : 一目均衡表
説明

| 線 | 性質 |
|---|---|
| 転換線(Conversion Line) | (9日間の高値+9日間の安値)÷2 |
| 基準線(Base Line) | (26日間の高値+26日間の安値)÷2 |
| 先行スパン1(Leading Span 1) | (転換線+基準線)÷2を26日先にプロット |
| 先行スパン2(Leading Span 2 | (52日間の高値+52日間の安値)÷2を26日先にプロット |
| 遅行スパン(Lagging Span) | 当日の終値を26日前にプロット |
実装
df_orig = pd.read_csv("stock_nikkei_3yrs.csv") df_orig.index = df_orig.date.apply(str2time) df_orig = df_orig.sort_index(ascending=True) max_9 = df_orig.high.rolling(window=9).max() min_9 = df_orig.high.rolling(window=9).min() df_orig["tenkan"] = (max_9+min_9)/2 df_orig["base"] = (df_orig.high.rolling(window=26).max()+df_orig.high.rolling(window=26).min())/2 xdate = [x.date() for x in df_orig.index] plt.figure(figsize=(15,5)) plt.grid() plt.plot(xdate, df_orig.close,color="b",lw=1,linestyle="dotted",label="Close") plt.plot(xdate, df_orig.tenkan,label="Conversion line") plt.plot(xdate, df_orig.base,label="Base line") senkou1 = ((df_orig.tenkan+df_orig.base)/2).iloc[:-26] senkou2 = ((df_orig.high.rolling(window=52).max()+df_orig.high.rolling(window=52).min())/2).iloc[:-26] plt.fill_between(xdate[26:], senkou1, senkou2, color="blue",alpha=0.2,label="Cloud") plt.legend(loc=4) plt.xlim(xdate[0],xdate[-1])
まとめ
けっこういろいろな指標が考えられているのですね。 株価だけじゃなくて、他の時系列データへのヒントにもならないかと思い、調べましたが、とてもいい勉強になりました。
ちょっと一つ移動平均線で試したいことがあるので、明日はそれをしようかなと思います。テーマは『ベイズ最適化』 それでは明日もお楽しみに!

















































